
AI
How Does an LLM Work? A Simple Guide for SME Owners
How does an LLM work, explained without jargon: books, tokens, maps of connections, and millions of corrections. Real examples for SME owners.
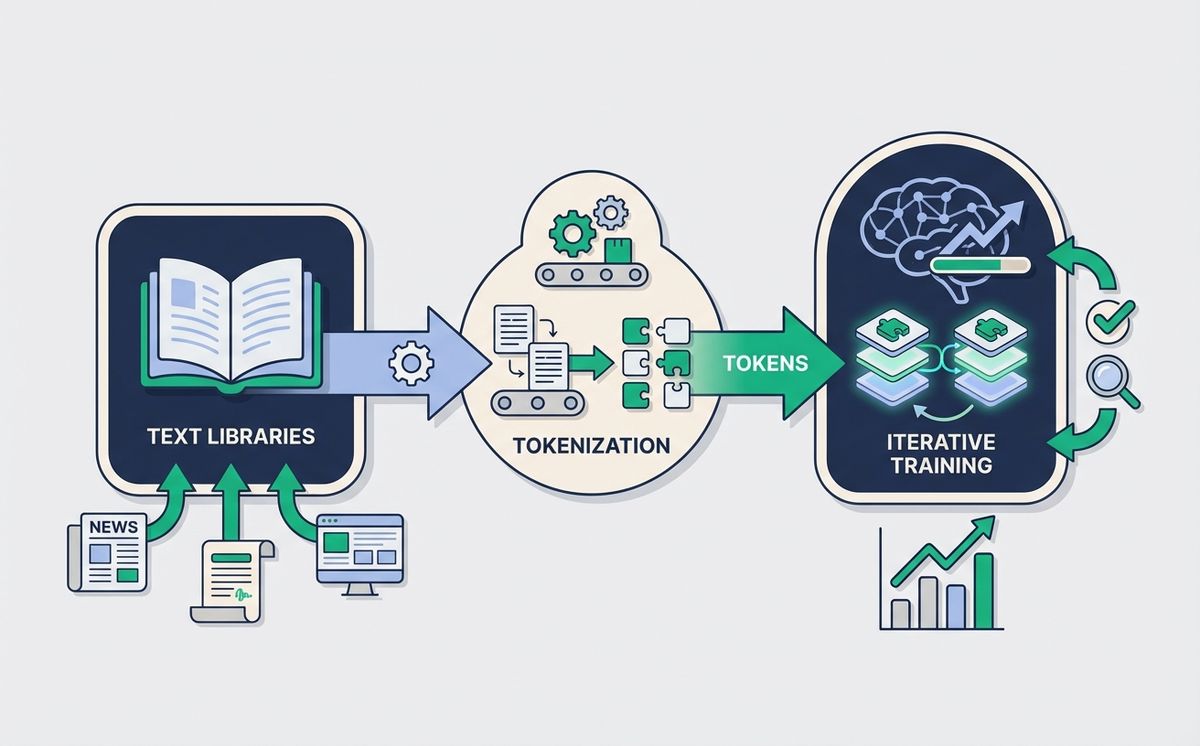
How does an LLM work? Imagine you have a time machine and a free afternoon. You use it to visit every library on the planet, scan every book, every letter, every legal document, and when you get back home you download the entire internet. You delete the duplicates, fix the typos, and hand that massive pile of text to a program. The program chops it into tiny pieces, connects them to each other, and learns to guess which word comes after which. Millions of times. Every mistake gets corrected. When it almost never fails anymore, you ask it to write something for you and the result sounds like a human.
That, stripped of all the marketing, is how an LLM works. Large Language Model. The kind of AI behind ChatGPT, Claude, Gemini, and everything your uncle calls “the artificial intelligence”.
I’ll walk you through the rest of the story in the next 10 minutes of reading. You’ll understand why an LLM fails when you ask it for real data, why it nails the job when you ask for a draft, and above all you’ll know what you can and can’t ask AI to do at your small business. No needless jargon, but with the correct names for things. If you’ve already wrestled with ChatGPT or Claude for work and want a foundation before diving in, take a look at our practical comparison of Claude and ChatGPT when you finish this article.
How Does an LLM Work? What It Really Is, Minus the Marketing
An LLM isn’t a person living inside your computer. It isn’t a database with every answer stored somewhere. It is, literally, a giant mathematical function that takes text in and sends text out. When you type “the capital of France is”, the model doesn’t look the answer up anywhere. It calculates which word is most likely to come next. “Paris” wins because, across the trillions of sentences the model has read, that sequence came up a lot.
The keyword here is probability. An LLM doesn’t “know” Paris is the capital of France. It knows that, statistically, “Paris” follows “the capital of France is” with very high probability. That’s a subtle but important distinction, and it’s the reason the same model sometimes nails the answer and sometimes makes things up with equal confidence.
Marta, who runs a real estate agency of eight people in Lisbon, learned that lesson the hard way. In 2024 she asked ChatGPT for average rental prices in her neighborhood for a client pitch. The model returned convincing numbers: 780 euros for a two bedroom, 1,050 for a three bedroom. It sounded reasonable. When the client checked the numbers against the national statistics office, it turned out they were inflated by 30%. Marta stopped using AI for almost a year. Later she understood why it had happened and went back to using it, but only for things it actually does well: summarizing, rewriting, structuring. Not for real data.
Here’s the first concept worth taking home: an LLM doesn’t look things up, it predicts. That prediction is as good as the data it was trained on and as bad as the accidental correlations it picked up along the way.
The Fuel: Corpus, Cleaning, and Why It Matters Where the Text Comes From
Everything an LLM knows is taught by its corpus, which is the technical name for “the huge pile of text used to train it”. To give you a sense of scale, models like GPT-4 or Claude Opus are trained on amounts of text measured in trillions of words. All of Wikipedia. Billions of web pages. Entire books, both classic and technical. Forums, code repositories, scientific papers, movie scripts.
Before that corpus enters the model there is a cleaning phase that most people ignore and that is absolutely critical. Engineers remove duplicates, because a text repeated a thousand times would teach the model that sentence is the norm. They filter low quality content, like spam, broken scrapes, or machine generated pages that say nothing. They apply rules to strip obvious personal data, although something always slips through. In serious labs, that curation phase takes more time and more money than the actual mathematical training.
Here comes a conclusion you rarely hear. Because the LLM only learns from what you feed it, the biases of your corpus become the biases of your model. If 70% of the text is in English and in technical register, your model will be better in English and in technical register. If medical documents are abundant but Spanish notary contracts barely appear, the model will answer a clinical question with precision and make up clauses when you ask for a contract. It isn’t malice. It’s pure statistics.
For the labs, the training corpus is a strategic asset. That’s why Anthropic, OpenAI, and Google are very careful about not revealing exactly what went inside. It’s one of the most important differences between one model and another, much more than the parameter count everyone talks about in marketing.
Chopping Up Language: Tokens, Numbers, and a Giant Map of Words
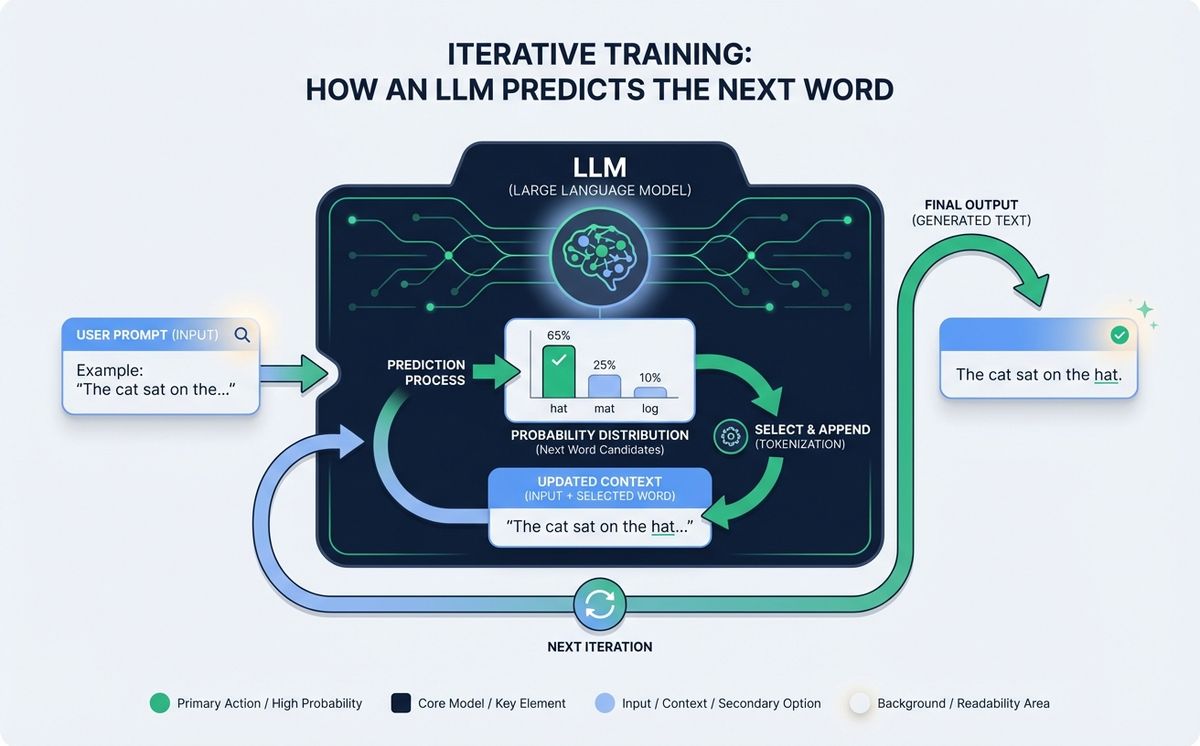
A computer doesn’t understand words. It understands numbers. Before text reaches the model, it passes through a phase called tokenization, which converts each chunk of text into a number. A *token* can be a complete word (“dog”), part of a word (“tion”), or even a punctuation mark. Modern models typically work with vocabularies of 30,000 to 200,000 different tokens.
When you type “hello, how are you?”, the model doesn’t see that sentence. It sees something like this sequence: [15496, 11, 17594, 34, 29326, 27315]. From there, each number is transformed into an embedding, which is a vector with hundreds or thousands of dimensions. Think of a vector as a very long list of coordinates. Each token lives in a huge mathematical space, and tokens with similar meanings are placed close to each other. “King” sits near “queen”, “Berlin” sits near “Paris”, and together they all form a giant map of relationships.
On top of that map runs the architecture that changed everything in 2017: the transformer. The canonical reference is the paper Attention Is All You Need by Vaswani and his team at Google. The transformer introduces a mechanism called *attention*, which lets each token look at every other token in the sentence at once and decide which ones matter for understanding it. It’s like reading a long sentence and highlighting with a marker the words that influence most what you’re processing at that moment. That ability to see the full context, in parallel and at scale, is what makes coherent responses possible.
If you want a really good visual intuition of how these vectors work under the hood, the neural networks series by 3Blue1Brown is probably the best free explanation that exists on the internet. You don’t need math to enjoy it. If you’d rather see this theory in code, the free Hugging Face course lets you tokenize text with a couple of lines of Python in under fifteen minutes.
Guessing the Next Word, Ten Trillion Times
With the corpus ready and the text tokenized, we arrive at the longest step: training. The goal is absurdly simple. The model is shown a sentence with the last word hidden and asked to guess what it is. If it guesses right, the connections that led to that answer are reinforced. If it misses, its internal weights are adjusted so the next time it misses a little less. That adjustment is called *backpropagation*, which is the technical name for “someone crossing out your mistake with a red pen and writing in the margin what you should have written”.
Here’s a concrete example. The model sees the sentence “The sun rises in the” and has to predict the next word. The first time, before it has learned anything, it answers “west”. A mathematical function tells it “no, it was east”. The weights associated with the connection between “sun rises in the” and “west” go down a little. The ones for “east” go up a little. Now multiply this process by trillions of sentences, by years of compute on GPU clusters that burn electricity like an office building, and you start to get a sense of the real cost of training a big model. Engineers talk about *epochs*, *learning rate*, *gradients*. We can translate it as: every time the model is wrong, it corrects a little. Repeat many, many times. That’s it.
The part that usually surprises people is that this process, applied at a crazy scale, makes capabilities emerge that nobody programmed explicitly. The model doesn’t learn “English grammar” as a concept. It learns that a subject tends to be followed by a verb that agrees with it. Nobody teaches it “Python code”. It learns that after def there’s usually a function name, a colon, and an indented block. No written rules. Just patterns.
Got the mechanism but unsure how to bring it into your company? That’s exactly our zone. At LetBrand we offer AI and automation consulting focused on SMEs that want to stop using ChatGPT as a toy and start integrating it into real workflows. No pitch, no empty promises.
Why an LLM Can Make Things Up Without Knowing It Is Lying
With all of the above in mind, the famous hallucinations stop being mysterious. An LLM doesn’t have an internal module that says “this I know for sure” and another that says “this I’m making up”. For the model, generating the correct answer and generating a coherent fabrication is exactly the same process: calculating which word comes next with the highest probability. If the correct answer showed up many times in training, it will generate it. If not, it will generate the sequence that resembles it most closely, and it will sound equally confident.
That’s why LLMs fail in weird ways. They invent academic citations with real authors, plausible titles, and DOIs that don’t exist. They quote case law that never happened. They give statistics with decimals and all, but without a verifiable source. It isn’t that they’re lying in the human sense. They can’t lie because they don’t know what the truth is. They just generate probable text.
There are several techniques to mitigate this. RAG (Retrieval Augmented Generation) connects the model to a database that does contain verified information, and forces the model to cite only what it finds there. *AI agents* can call external tools to fact-check before responding. If you want to go deeper on agents, our guide on how to build an AI agent from scratch unpacks this in detail. There are also extended reasoning models that take more time to self-verify before answering.
But the underlying principle stays the same: an LLM doesn’t know anything. It predicts. When it gives you an important answer, verify it. Always. No exceptions. That attitude alone separates the SMEs that get value from AI from the ones that burn their fingers.
What All of This Means for Your SME
Now the part that actually matters. What do I do with this tomorrow at my company? Understanding the mechanism gives you three very practical things.
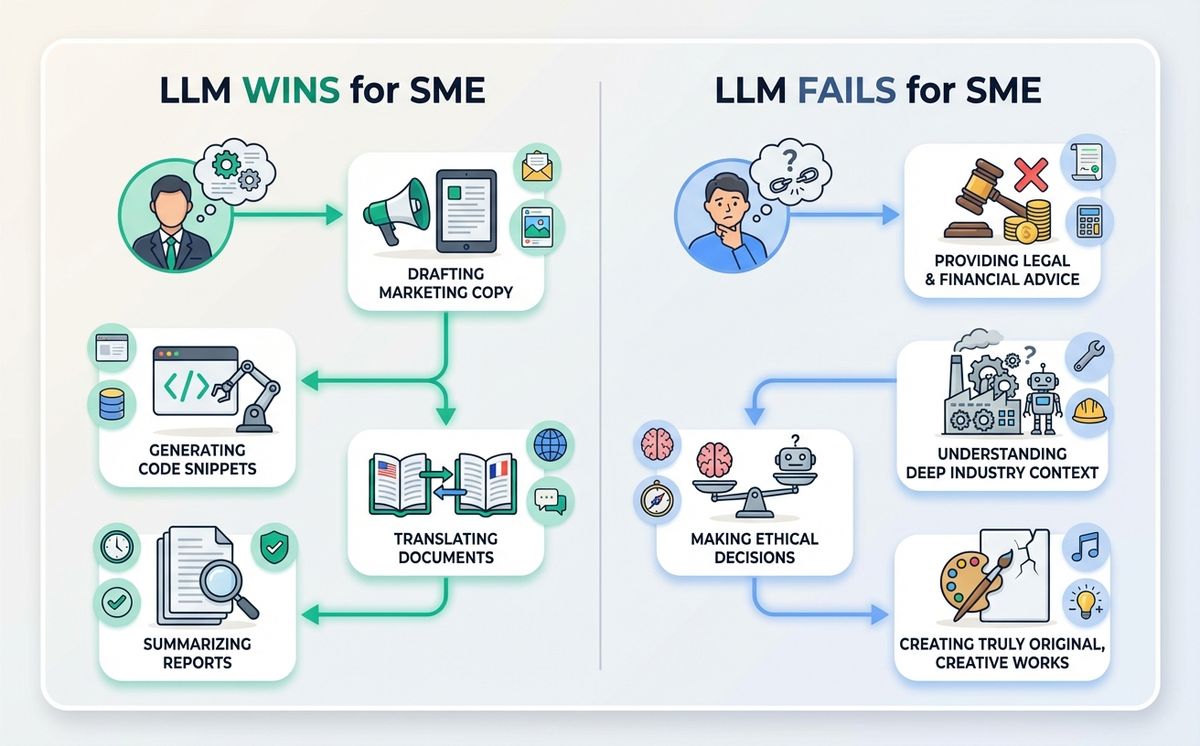
The first is a filter for deciding which tasks you can trust the model with and which you cannot. The tasks where an LLM shines are the ones where you bring the content and the model brings the form: summarizing a client email, rewriting a text with a specific tone, translating while keeping nuance, drafting a sales proposal from your notes, classifying support tickets, cleaning messy data. In all of those, the model doesn’t have to remember anything. It just transforms what you give it.
The tasks where an LLM fails are the ones that require fresh information, verifiable data, or decisions with real consequences without oversight. Current prices, live regulations, case law, CRM figures, legal calls. There, either you connect the model to a live data source using RAG or agents, or you burn your fingers like Marta did.
The second thing you gain is realistic expectations about vendors. When somebody pitches you “AI that makes autonomous decisions in your company”, you now know that requires serious architecture: agents, connected tools, verification, logging, human oversight. It isn’t magic. It’s engineering. The price should reflect that. If it’s cheap, it usually means you’re buying a well crafted prompt on top of a standard model, nothing more. If you want to evaluate open source tools before committing to closed vendors, our piece on what OpenClaw is is a good place to start.
Javier, CTO of a 15 person logistics startup in Berlin, ran exactly that exercise last year. He stopped asking AI to “make decisions” and started asking it to organize information and draft texts. He set up three very simple flows with Claude and a couple of scripts: one that summarizes incoming emails by priority, one that drafts replies the team only has to tweak, and a third that tags repeated issues so the team can spot patterns. His team now saves 12 hours a week. Nobody reviews made up data because the AI never generates any: it only works with text the team’s already written.
The third thing you gain is vocabulary to talk to technical vendors. Knowing what a token is, what an embedding is, what a context window is, and what *fine tuning* means lets you have an adult conversation with whoever is selling you a solution. You won’t build the model yourself, but you’ll be able to ask the right questions.
One Last Thought Before You Close the Tab
If you made it this far, you now understand how an LLM works better than 95% of the people who use one every day. Let’s recap what we’re taking home.
- An LLM is a mathematical function that predicts the next word, not a database of answers.
- It learns from a huge corpus of text, and the biases of the corpus become the biases of the model.
- It chops text into tokens, turns them into vectors, and works on a giant map of relationships between them.
- It trains by failing and correcting trillions of times, until it almost never fails.
- It doesn’t know what’s true. It predicts what’s probable. That’s why it hallucinates, and why you’ve got to verify the important stuff.
- At your SME, use it to transform text you provide. Avoid it for supplying data you can’t verify.
If after reading this you think there are flows in your business that fit and others that don’t, and you want an honest opinion on where to start, we can have a no strings attached conversation. At LetBrand we’ve been helping SMEs bring AI into their operations for years, without smoke and mirrors. Book a 30-minute call (free, no pitch) to audit which parts of your business make sense to automate with AI and we’ll tell you honestly whether it’s worth it or not. Sometimes the answer is not yet. That’s useful information too.
Related Posts

Agent skills are the open standard that works across Claude Code, GitHub Copilot, Gemini CLI, and 45+ AI agents. One file. Every tool. Zero repetition.
Read more
Every match weekend, Spain Cloudflare blocks take down online shops, payment systems and GPS apps. Pirates keep watching. Your business pays the bill.
Read moreReady to start your project?
Let's talk about how we can help your brand grow with a personalized digital strategy.
Contact us